뭐든 새로운 것이 나오면 거대한 칭송과 거대한 반대가 동시에 튀어 오릅니다. 그러다 1년 정도 지나면 차분해지고 거품을 빼고 들여다봅니다. NFT가 그랬고 앞으로 나올 IT 관련 기술 열풍들이 그럴 겁니다. 지금 전 세계는 챗GPT 광풍에 휩쓸리고 있습니다. 연일 기자들은 챗GPT 기사를 쓰고 있습니다. 그러나 대부분의 기사는 쭉정이 같은 기사로 챗GPT가 무슨 신인양 미래를 예측하라고 하고 분명히 2021년까지 학습했다고 했는데 2022년 월드컵 우승국 맞추라고 하는 등등의 무식한 질문을 하고 있습니다.
따라서 챗GPT를 제대로 보려면 챗GPT를 배워야 합니다. 최소한 원리라도 알면 좋습니다.
챗GPT는 인간의 신경망을 흉내 내서 만든 인공신경망 대화형 모델
위 2개의 영상 시리즈를 보면 챗GPT를 이해할 수 있습니다. 각각 3개, 2개의 영상 시리즈이니 다 보시길 바랍니다. 전 1개의 시작 영상만 담았습니다.
챗GPT는 형태는 챗봇이라고 할 수 있습니다. 질문하면 대답하는 서비스입니다. 영문으로 질문하면 더 빠르고 길게 대답하지만 한글로 질문을 해도 됩니다. 다만 느리고 자료량이 적어서 영문으로 질문하는 것이 더 좋습니다만 한글로 질문해도 지금까지 나온 그 어떤 챗봇보다 똑똑하고 뛰어납니다. 무엇보다 사람처럼 대답을 해주고 어떤 질문에도 척척 대답을 하기에 기존 챗봇 서비스와 비교를 할 수 없습니다.
이루다와 비슷하다고 할 수 있지만 이루다는 이루다 안에서 대화를 나눈 그 데이터를 바탕으로 학습하는데 반해 루머에 따르면 챗GPT의 기반인 GPT-3는 파라미터가 1750억 개이고 곧 나올 GPT-4는 100조 개라는 소문이 흘러나오고 있습니다. 그래서 GPT-4는 인간과 인공지능을 구분하는 테스트인 튜링테스트를 통과할 것이라는 소문도 들리게 되네요. 튜링테스트를 통과하게 되면 우리 인류는 사람이 아닌 또 다른 인격체와 공존을 하는 첫 인류가 될 것입니다.
위 챗GPT 영상을 보면 아시겠지만 챗GPT의 인공지능은 스스로 공부하는 비지도 방식의 기계학습(머신러닝)을 하는 인공지능 모델입니다.

10년 전에는 개와 고양이를 구분할 때 하나하나 사람이 개와 고양이를 직접 인공지능에 가르쳐야 했습니다. 이런 식으로 지능을 키우려면 많은 사람의 손길이 필요하고 시간도 오래 걸립니다. 프로그래밍이라는 것도 그렇습니다. 컴퓨터에게 개와 고양이 사진을 입력하고 이렇게 생긴 것은 개, 이렇게 생긴 것은 고양이라고 프로그래밍을 짰습니다. 이 방식의 맹점은 프로그래밍을 짜는 시간도 인력도 많이 들지만 고양이와 비슷한 삵의 사진을 보여주면 그게 뭔지 몰랐습니다.
인간은 삵을 보면 고양이와 비슷하지만 뭔가 달라라면서 추론을 하기 시작하죠. 고양이처럼 보이니까 고양잇과일 것 같은데 고양이와 다른 특징들을 추합하고 추론하면서 데이터를 축적한 후에 하니의 개념을 정립해서 분리하죠. 이런 방식으로 인간은 사고합니다. 모르는 건 추론을 합니다. 이 인간의 세상에 대한 학습 방법을 따라한 것이 기계학습(머신 러닝)입니다.
기계학습은 개와 고양이라는 개념을 인간이 가르쳐주지도 않았는데 스스로 학습해서 구분을 합니다. 야옹하고 소리를 내고 점프를 잘하고 날렵하고 눈동자가 낮에는 줄어들어드는 동물을 고양이라고 스스로 개념을 정립합니다. 그래서 어떤 개와 고양이 사진을 보여줘도 잘 구분합니다. 심지어 인간보다 구분의 정확도가 더 높습니다.
인간은 데이터와 해답을 주면 인공지능이 기계학습을 통해서 규칙을 스스로 찾아냅니다. 놀라운 건 이 기계학습을 가능하게 하는 코드가 1천 줄도 안 된다는 겁니다. 그럼에도 기계학습을 하다가 인공지능이 오류가 발생하거나 해결하기 힘든 문제가 나오면 인간의 손길을 필요로 합니다. 가끔 호출해서 프로그래머님 이거 봐주세요라고 합니다. 그런데 기계학습이 딥러닝이라는 심화학습 기능을 장착하면서 그 마저도 하지 않게 됩니다.
막히면 더 깊게 공부하고 다양한 데이터를 공부해서 스스로 해결책을 찾아내면서 진화를 거듭하고 지능을 스스로 키웁니다. 이는 혁신적인 변화입니다. 기존에는 사람이 자동차와 새를 구분하는 법을 컴퓨터에 알려주려면 많은 시간과 노력이 필요한데 이제는 데이터를 제공하고 이런 결과를 내줬으면 좋겠어라고 데이터와 요구하는 결과값을 입력하면 자기가 알아서 자동차와 새를 구분하고 새는 어떤 새가 있고 특징이 뭐고 인간이 좋아하는 새는 뭔지 별별 것을 다 학습하고 인간에게 놀라운 결과값을 제공합니다.
그러나 이런 기계학습에도 문제점은 있습니다. 특히 챗GPT 같은 언어 모델이 성차별이나 인종차별의 말을 해서 큰 논란이 되곤 했죠. 인간의 데이터를 학습하다 보니 인간들이 쓰는 편견과 욕설과 비난을 그대로 배웁니다. 사람은 익명의 뒤에 숨어서 인종차별, 지역 비하, 성차별적인 폭언을 할 수 있습니다. 그러나 인간에 대한 서비스를 해야 하는 인공지능이 그러면 안 되죠.
그래서 기존의 언어 모델 인공지능들은 이 성차별, 인종차별 등의 문제점으로 많은 비난을 받았습니다. 챗GPT는 기계학습만 하면 욕도 하고 폭언도 하는 등의 문제점을 지도학습으로 다스렸습니다. 인간이 직접 개입해서 이 말은 하면 안 돼! 이건 인종차별적인 말이야 하지 마! 식으로 지도 학습을 시켜줬습니다. 그러나 언제까지 인간이 개입할 수도 없고 비용도 늘 수 밖에 없습니다. 그런데 약 2% 비용만 더 추가해서 지도학습을 해줬더니 챗GPT가 나쁜 언어를 사용하지 않게 되었고 심지어 지도 학습 내용을 학습한 챗GPT가 스스로 지도 학습을 한 인간을 흉내낸 인공지능을 만들어서 스스로 답변에 대한 채점을 하는 강화학습을 했습니다.
한 마디로 인간이 좋아할 만한 결과값을 귀신같이 알아서 내놓기 시작한 게 요즘 인공지능 기계학습(머신러닝)과 딥러닝(강화학습)입니다.
챗GPT를 품을 MS 빙 검색
많은 사람들이 구글 검색은 끝나다고 합니다. 그럴 리 없습니다. 챗GPT는 검색 보조도구이지 검색엔진을 뛰어 넘을 수 없습니다. 챗GPT는 과거 사실과 데이터를 뱉어내는 뛰어난 능력이 있지만 어떤 개인적인 의견이나 여러 가지 리뷰를 뱉어낼 수 없습니다.
예를 들어서 '키아누 리브스'의 2023년 현재 나이에 대한 대답은 잘 하지만 영화 '타이타닉'에 대한 감상을 담지는 못합니다. 다만 사람들의 의견 추합과 소개는 할 수 있고 이걸 바탕으로 개인적인 경험과 시선을 녹여서 글 쓸 때는 좋습니다.
챗GPT가 오픈 AI에서 만들었다고 해서 작은 기업이라고 소개하는 기사도 보이던데 오픈 AI 설립에 큰 도움을 준 회사들이 많습니다. 지금은 MS사가 수조 원을 투자하고 있고 현재도 수조 원을 넣고 있습니다. 그리고 MS사의 인기 없는 검색 서비스인 빙에 이 챗GPT 기능을 넣어서 공개할 예정입니다.
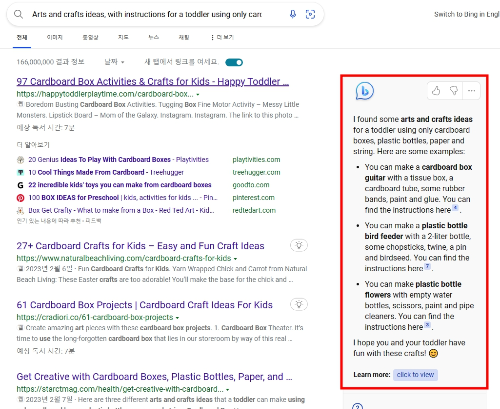
현재 미리 체험할 수 있게 했는데 살펴보니 검색 결과 오른쪽에 챗GPT의 답변을 나오게 했네요. 챗GPT는 간단한 사실과 정보를 아는데 특화된 챗팅 검색 서비스로 정착될 것입니다. 또한 구글도 비슷한 기능을 선보일 겁니다.
검색서비스가 챗GPT 때문에 사라지지는 않을 겁니다. 지금 이 글을 읽는 분들도 챗GPT의 답변보다 길고 다양한 이야기를 하기에 읽는 것이지 카메라 사양만 알길 원한다면 챗GPT를 이용하는 게 더 현명하고 편할 겁니다. 다양한 정보와 시선과 좀 더 깊은 정보나 내용을 얻고 싶으면 블로거나 유튜버가 생산한 콘텐츠가 중요합니다.
오히려 챗GPT 같은 챗봇 서비스가 검색 엔진에 붙으면서 검색 엔진 사용률은 더 높아질 겁니다.
간단한 정보 검색에 뛰어난 구글
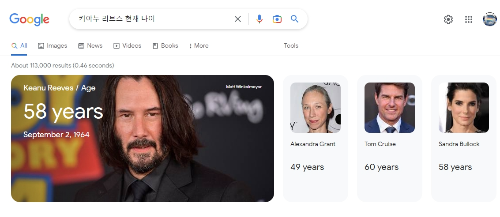
그럼 현재 구글의 검색 수준은 어떤가 보죠. UI와 검색 결과가 먹기 좋게 내놓지 않기로 유명한 구글 검색이 요즘 많이 달라졌습니다. '키아누 리브스 현재 나이'를 검색하니 58살이라고 알려줍니다. 놀란 것은 사진을 배경으로 하고 출생년도까지 표시를 합니다. 옆에는 키아누와 연관이 있는 배우들의 나이까지 선보이고 있네요.
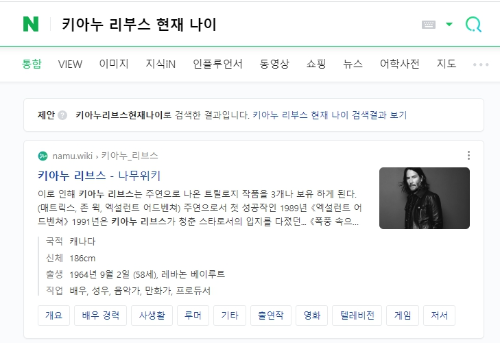
네이버는 나무위키에 의탁하네요.
다음은 검색 서비스라고 하기 어려울 정도로 망가졌습니다. 저세상 검색 결과를 내놓고 있네요. 검색율이 3%도 안 되는 회사라서 발전 가능성이 낮습니다.
남산타워의 높이를 검색해보면 다음은 유튜브 영상부터 뱉네요. 여기는 서비스 접는게 낫지 않을까 하는 생각까지 듭니다.
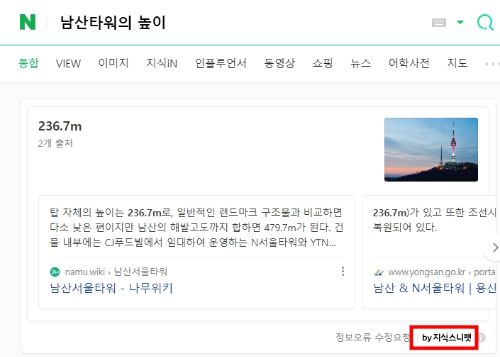
네이버는 지식스니펫으로 또 다사 나무위키 내용 중 일부만 따서 상단에 노출하고 있습니다. 요즘 검색엔진은 스니펫 기술을 이용해서 웹페이지에서 내가 원하는 정보만 따서 최상단에 노출하고 있습니다. 나무위키 정보에 오염이나 오류가 있으면 바로 잘못된 정보를 제공할 수 있습니다.
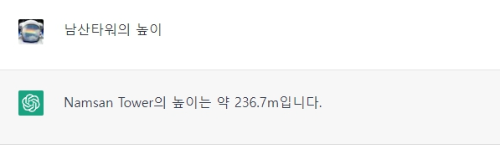
남산타워 높이를 챗GPT에 물어보니 236.7m로 바로 대답하네요. 똑똑합니다. 다음 보다 똑똑해요.
구글도 대답을 잘 하는데 나무위키가 아닌 신뢰도 높은 관광공사 홈피에서 따왔네요. 나무위키가 신뢰도가 낮다는 건 아닙니다. 가끔 오정보도 올라오는게 문제죠.
놀라웠던 것은 구글은 특정 카메라 무게를 검색하니 스니펫 답변으로 특정 홈페이지에서 자료를 추출해서 보여주더라고요. 당연히 한국 홈페이지에서 추출했구나 했는데

아닙니다. 위 사이트 보세요 한국어 홈페이지로 한국인이 운영하는 것 같습니다. 그런데 뭔가 어색합니다. 교포 말투 같기도 하고요.

혹시나 하고 리로딩을 하니 놀랍게도 아일랜드 홈페이지네요. 검색 결과에 구글의 뛰어난 문맥 번역 기술을 이용해서 홈페이지를 통째로 번역해서 보여줍니다. 이렇게 되면 한글로 검색해도 해외 자료, 영문 자료를 번역해서 검색 결과로 내놓겠네요. 검색어 언어의 장벽이 허물어지고 있네요.
반대로 한국어 정보를 영문으로 번역해서 해외 사용자들에게 소개하기도 하겠네요. 이렇게 되면 미래는 번역 기술이 뛰어난 구글에 검색 노출이 되는 것이 중요한 시대가 될 것 같네요. 구글 검색에 잘 노출되려면 구글 검색 최적화가 좋은 워드프레스가 근 미래에 각광을 받을 듯합니다. 그래서 블로거들은 네이버나 티스토리보다 워드프레스에 한글로 된 콘텐츠 많이 올리면 좋을 듯하고 저도 준비하고 있습니다.
챗GPT의 근간이 되는 기술은 구글에서 개발한 기술들입니다. 따라서 구글이 지금은 챗GPT에 위기를 받는 것 같고 실제로 구글의 주요 수익원이 애드센스라는 광고라서 위기가 될 수 있습니다. 챗GPT에는 광고 달기 쉽지 않으니까요. 그래서 유료화한다고 하잖아요. 다만 빙은 무료로 제공해서 방 검색율을 올려서 광고 수익을 올릴 생각인가 봅니다.
구글은 자신들이 만든 챗봇으로 간단한 질문을 해결하고 깊이 있는 내용이나 질문은 다른 콘텐츠 생산자인 블로거나 웹페이지 검색 결과로 꾸준히 애드센스 광고 수익을 올릴 것으로 보입니다. 챗GPT는 만능도 신도 아닙니다. 또한 현재의 열풍은 과장도 크죠. 자연스럽게 그냥 좀 똑똑한 챗봇서비스로 정착될 듯하네요.
문제는 구글은 자체 챗봇을 준비하고 있지만 네이버 특히 다음은 내놓을지 모르겠네요. 말로는 올 상반기에 내놓겠다고 하던데 어떻게 나오나 지켜봐야겠네요. 현재 네이버 블로그 맞춤법 검사기의 수준을 보면 일도 기대가 안 됩니다.



