요즘 뜨는 단어가 멀티 모달(Multi-Modal)입니다. 멀티 모달은 다양한 감각 기관을 통해서 들어온 정보를 다양한 방식으로 정보를 주고받는 것을 말합니다. 쉽게 말해서 우리가 정보를 주고받을 때 시각, 청각, 후각, 촉각, 미각 등으로 정보를 전달합니다.
인간은 다양한 감각 기관으로 대화를 하고 정보 전달을 합니다. 그러나 AI는 시각 정보를 시각으로 청각 정보는 청각으로 전달합니다. 그러나 생성형 AI가 나오면서 텍스트로 명령하면 시각으로 또는 텍스트로 청각으로 전달할 수 있습니다.
그러나 앞으로는 영상이나 사진을 보고 텍스트로 정리하고 설명하는 AI, 냄세를 텍스트로 설명하는 AI, 텍스트를 음악으로 또는 냄새로 만들어주는 AI 등등 다양한 매체의 정보를 습득하고 이걸 또 다양한 매체로 만들어주는 AI가 나올 듯합니다.
음성 파일을 텍스트로 만들어주는 네이버 클로바노트
전 세계가 인공지능 특히 생성형 AI에 열광을 하고 있습니다. 이에 네이버는 하반기에 네이버 챗GPT인 '서치 GPT'를 선보이고 카카오브레인인 이미지 생성형 AI인 칼로 2.0을 최근 선보였습니다. 그러나 전 한국 대형 IT 기업의 AI 기술력을 높게 보지 않습니다. 네이버의 서치 GPT도 큰 기대가 안되고 이미 세상에 선보인 카카오 브레인의 칼로 2.0은 조악함에 깜짝 놀랐습니다.
카카오가 최근 정부가 주도하는 AI연합체에 빠진 이유도 카카오가 AI 쪽 사업에 자신감도 기술력도 딸리기 때문이 아닐까 합니다. 지금 당장 굶어 죽게 생겨서 티스토리 배를 갈라서 황금알을 꺼낼 정도로 급박하고 오늘내일하는 회사가 무슨 AI에 투자하겠어요. 네이버도 검색 엔진 고도화를 최근에 좀 하는 듯 하지 수십 년 동안 저질 검색엔진으로 운영하는 회사가 무슨 구글과 빙과 오픈 AI와 겨루겠습니까?
제가 이런 말을 하는 이유는 여러 가지가 있는데 먼저 네이버의 저질 블로그 에디터와 함께 네이버 클로바노트를 사용하면서 이 정도밖에 안되나? 하는 실망감이 드네요. 물론 좋은 점, 고마운 점도 있지만 실력은 높지 못하네요. 직접 보여드리죠.
카카오는 카카오 브레인이라는 기술을 개발하는 자회사가 있지만 여기서 뭘 하는지 알 수가 없습니다. 카카오 문화 특유의 폐쇄적이고 독단적인 운영으로 인해 뭘 하는지 알 수가 없습니다. 알리지도 않고요. 그나마 네이버는 적극적으로 알리고 우리가 사용할 수 있는 기술을 선보이고 있네요. 네이버는 하이퍼크로버라는 미래 성장 동력을 키우고 있습니다. 네이버의 AI 기술력을 볼 수 있습니다.
네이버 클로바노트는 음성 녹음 파일을 올리면 그걸 텍스트로 전환해 주는 서비스입니다. 텍스트를 음성으로 읽어주는 기능의 역버전이죠. 그러나 텍스트를 음성으로 읽게 하는 건 쉬워요. 목소리와 성조와 발음이 천차만별인 목소리를 텍스트로 뽑아내는 것이 쉽지는 않습니다. 그러나 구글은 이걸 아주 잘합니다. 어제도 스마트 셋톱박스에 구글 버튼 누르고 음성 명령을 내리면 찰떡같이 알아들어서 역시 구글의 음성인식 기술이라고 엄지 척을 해줬네요.
네이버 클로바노트는 무료입니다. 다만 1달에 600분 정도만 무료로 사용할 수 있습니다. 즉 음성 파일 녹음 길이가 600분 그러니까 총 10시간 정도만 무료입니다만 여러 계정 이용하면 꽤 오랜 시간 사용할 수 있습니다. 물론 수많은 음성을 텍스트로 저장 기록해야 하는 일을 하는 분은 돈 주고 사용해야죠. 그럼 돈 주고 사용할 만큼 인식력이 어떤가 봤습니다.
<엔니오 : 더 마에스트로> GV를 동영상이 아닌 음성으로 녹음해서 네이버 클로버노트에 올렸습니다. fla 파일은 지원을 안 해서 변환을 해야 했습니다.

음성의 종류를 선택해 줍니다. 일반 대화인지 회의인지를 선택해 주면 그에 맞게 발언자를 구분할 수 있습니다.
그냥 강연이라면 혼자 떠들기에 텍스트만 쭉쭉 나열되지만 GV 같이 여러 사람이 모여서 수다를 떠는 회의 형식이면 회의를 선택하면 됩니다.
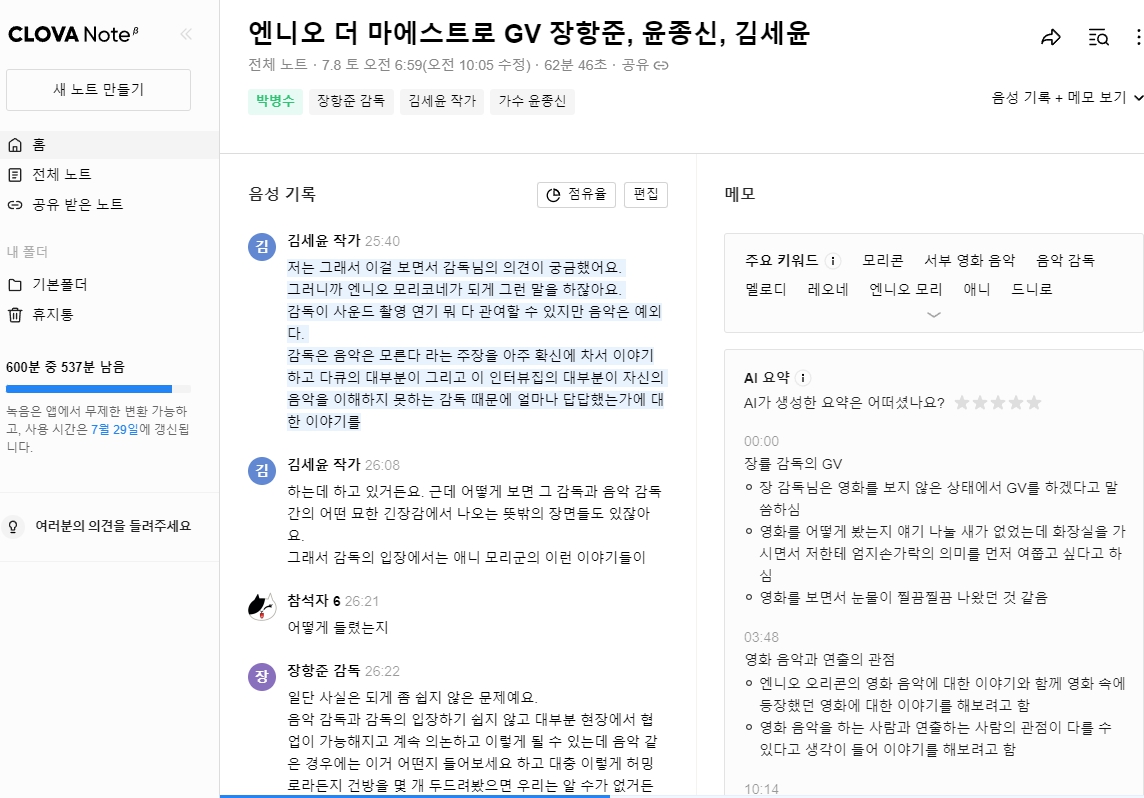
UI는 이렇게 생겼습니다. 음성 파일을 텍스트로 변환하는 데는 1분 안 걸립니다. 금방 하네요. 오른쪽에 보면 AI 요약이 있습니다. 음성 내용을 인지하고 핵심이 이거다라고 말하는 AI 요약이라고 하는데 솔직히 말해서 AI 요약 정말 품질 저질입니다. 텍스트를 이해하고 내놓는 것 같지 않다고 할 정도로 별로네요.
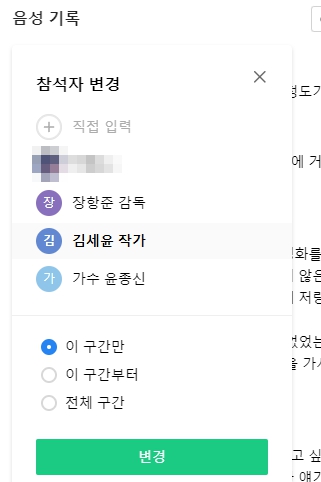
이 GV는 장항준 감독, 윤종신 가수, 김세윤 작가가 참석했는데 총 3명의 화자가 등장합니다. 출연자의 목소리가 다르기에 같은 목소리끼리 묶어줍니다. 다만 이름은 모르기에 내가 직접 참석자 이름 옆을 클릭해서 직접 이름을 입력해서 전체 구간으로 설정하면 일괄 변경이 됩니다.
그럼 목소리 구분력은 좋냐? 꽤 좋습니다. 꽤 좋아요. 괜찮습니다. 남성 3명인데도 잘 구분을 합니다. 물론 100%는 아닙니다. 문제는 말이 겹칠 때가 있죠. 두 사람이 동시에 말하면 그건 구분 못합니다. 오디오 겹치면 안 됩니다.
네이버 클로바의 최대 단점 외국어 인식력이 너무 떨어진다.
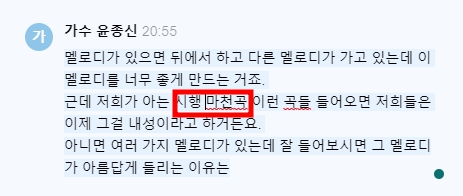
네이버 클로바는 텍스트 인식력이 좋습니다. 수년 전만 해도 너무 못알아 들어서 외계어로 적어내던데 네이버 클로바는 기계학습을 오래 하고 많이 해서 그런지 한국어 인식력은 아주 좋네요. 이게 장점입니다. 무료 프로그램 치고는 아주 좋네요. 유튜브 영상에서 음성 추출한 후에 텍스트로 변환 후에 자막 입힐 때 좋죠.
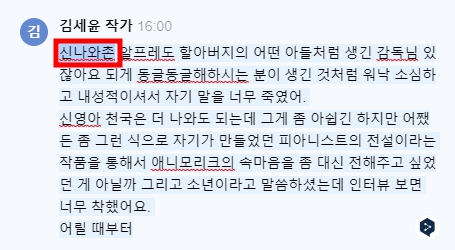
그러나 영어 인식력은 너무 안 좋아요. 발음 좋기로 소문난 윤종신이 '시네마 천국'이라고 말했는데 '시행마천곡'이라고 하질 않나 김세윤 작가의 말은 '신나와촌'이라고 하질 않나 많이 사용하는 단어 인식력은 좋은데 고유명사나 외국어는 인식력이 너무 떨어지네요.
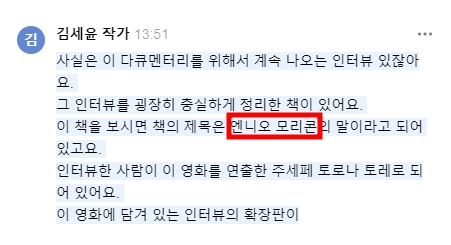
엔니오 모리꼬네를 엔니오 모리콘은 애교이고 애니모리크라고 하는 등등 엔니오 말할 때마다 내가 직접 편집을 눌러서 텍스트를 수정해줘야 했습니다.
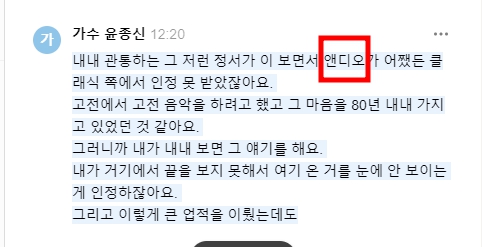
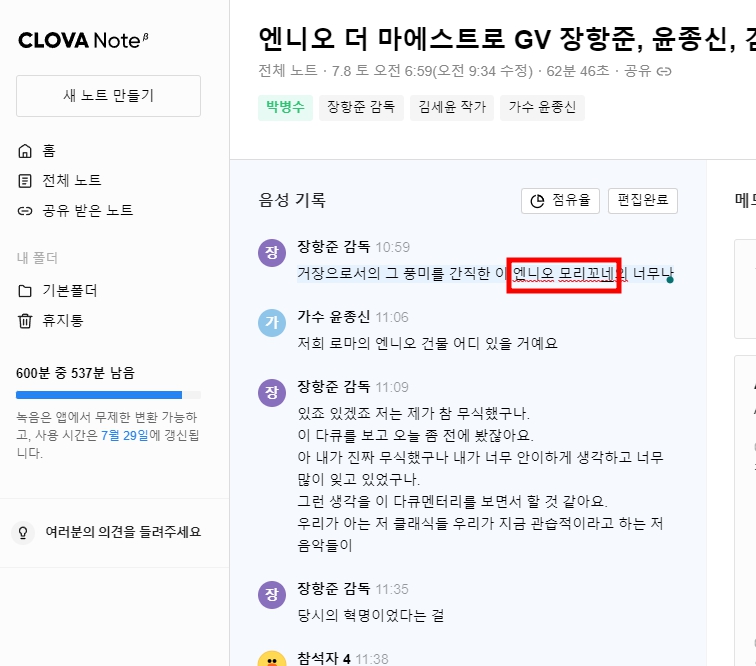
단 한 번도 '엔니오 모리꼬네'로 적질 못하네요. 이게 네이버 클로바의 가장 큰 문제점이자 단점입니다. 학습 데이터셋이 적어서 그런 것이지만 요즘 생성형 AI는 학습 데이터를 스스로 만들어서 학습할 정도인데 그런 기술력은 없나 봅니다. 생성형 AI도 아니고요. 단순 기계학습을 통한 기술입니다. 이걸 보면 과연 네이버가 AI 기술력이 좋은가 글로벌에서 살아남을 수 있을까 하는 생각도 듭니다.
그렇게 1시간 GV 내용을 수정하는데 무려 3시간 이상 걸렸고 그것도 하다 말았습니다. 하나하나 음성을 들으면서 확인해야 해서 기본 1시간 이상이라고 해도 워낙 부정확한 곳이 많아서 손이 많이 가네요. 다 만든 음성 >> 텍스트 변환 파일은 상단에서 음성 기록 다운로드를 통해서 워드나 메모장 파일로 만들 수 있습니다.



