영화를 보면 주인공이 저길 확대해봐!라고 하면 그 부분을 확대해서 보여줍니다. 그런데 이거 거짓입니다. 우리가 보는 CCTV 화면을 확대하면 고해상도 영상이 아니면 확대해도 선명하게 보이지 않고 픽셀이 보이는 모자이크 형태로 보입니다.
그러나 영화적 허용을 통해서 주밍을 해도 깨끗하게 보이죠. 아니면 주밍을 한 화면이 모자이크처럼 보이면 엔터 한 번 치면 선명해지게 보이는 모습을 볼 수 있죠. 그러나 이런 기술은 아직 구현되지 않았습니다. 그러나 이 어려운 기술을 구글이 선보였습니다.
딥러닝으로 모자이크 이미지를 복원해주는 구글 브레인 기술

작년 최대의 기술 이슈는 알파고를 통한 딥러닝 기술입니다. 이 딥러닝은 기계 학습과 연계 된 기술로 흔히 인공지능(A.I)라고 불립니다. 이 딥러닝 기술은 인간의 뇌를 벤치마킹한 기술로 스스로 학습을 한 후 그 경험을 쌓아가면서 보다 정교한 판단을 하는 기술입니다. 수 많은 시행착오를 거쳐서 스스로 최적화 된 방법을 찾는 자기 학습 기술입니다. 따라서 인공 지능이 가장 하기 어려워하는 추론을 할 수 있습니다.
즉 비슷한 2가지 중에서 어떤 것이 좋은 지를 이전에는 판별하기 어려웠다면 딥러닝을 통한 인공 지능은 스스로 판단을 할 수 있습니다. 그 판단력이 인간보다 점점 뛰어난 모습을 보여주고 있네요.
이 딥러닝을 이용한 구글 브레인이 고해상도 이미지를 8 x 8(64)픽셀로 변환 한 이미지를 다시 원본 이미지로 추측하는 기술인 'Pixel Recursive Super Resolution'을 발표했습니다.
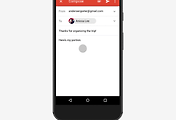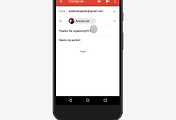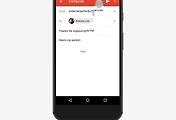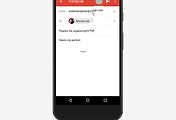
위 이미지를 보면 오른쪽 사진이 '소스 이미지'이고 이걸 8 x 8 픽셀 크기로 압축 한 것이 8 x 8 샘플입니다. 이 8 x 8 샘플 이미지를 구글 브레인이 딥 러닝 기술을 이용해서 예상한 원 본 이미지인 32 x 32 샘플 이미지로 변환했습니다. 8 x 8 샘플 이미지에서 16배의 해상도로 업 스케일 된 예상이미지는 8 x 8 샘플 이미지의 뭉게진 이미지가 아닌 어느 정도 사람 형태의 모습을 잘 보여주고 있습니다.
즉, 맨 오른쪽 사진이 원본, 이걸 압축한 것이 맨 왼쪽 사진 이 왼쪽 뭉개진 사진을 가지고 구글 브레인 기술을 이용해서 좀 더 높은 해상도로 복원한 것이 중간 이미지입니다. 보시면 아시겠지만 중간 이미지와 오른쪽 원본 이미지가 똑같지는 안지만 대충 비슷한 느낌입니다. 눈 부분을 보면 맨 아래 여자 이미지에서 원본은 눈이 더 큰데 구글 브레인이 복원한 이미지는 눈이 좀 작네요. 그래도 이 정도면 엄청난 발전이자 기술입니다.

구글 브레인은 2개의 신경망 훈련을 통해서 이미지를 예측하고 있습니다. 하나는 고해상도 이미지를 압축 한 데이터와 8 x 8 샘플을 비교해서 패턴과 색상을 인식하는 'conditioning network'와 또 다른 하나는 PixelCNN을 이용해서 고해상도의 자세한 부분을 메꿔주는 'prior network'입니다. 2개의 신경망 기술을 결합해서 예측 이미지를 만듭니다.


이런 기술을 통해서 8 x 8 샘플 이미지로부터 4개의 예측 이미지를 끄집어 냈습니다. 보시면 예측 이미지가 조금씩 다릅니다.

Pixel Recursive Super Resolution기술이 완벽한 것은 아닙니다. 그러나 이 기술을 점점 가다듬으면 "거기 확대 해봐!"라는 영화 속 대사가 허구가 아닌 실제가 될 날이 오겠네요